Today we’ve released Numbas v3.0. It’s the thing I’m second-most proud of producing in the last year (my daughter was born last October).
The marking code at the heart of Numbas has been completely rewritten, to make it much easier for question authors to change how students’ answers are marked. This has also allowed the introduction of custom part types, to make it easier to use and reuse different marking algorithms.
Marking algorithms
Until now, Numbas has had a few built-in part types, each with their own marking algorithms written in JavaScript. They were configurable to an extent, but the structure of the marking process for each part type was fixed. to do anything different, question authors would have to override the standard behaviour with JavaScript code, which isn’t very easy to write or test.
I’ve come up with a much better system: each part has a “marking algorithm” script, written in the same JME syntax used elsewhere in Numbas, which specifies how the part is marked.
The marking algorithm is responsible for:
- Rejecting the student’s answer if it’s invalid. If the answer is rejected, no credit or feedback will be given and the student must change their answer before resubmitting.
- If the student’s answer is valid, assigning credit and giving feedback messages.
The marking algorithm comprises a set of marking notes, which are evaluated similarly to question variables: each note produces a JME value and a list of feedback items, which can be used by other notes. In this way, you can build up a set of discrete observations about the student’s answer, use those to make decisions about how to proceed with marking, and finally collate the feedback generated and present it to the student.
Here’s the marking algorithm for the “Number entry” part type:
studentNumber (The student's answer, parsed as a number):
if(settings["allowFractions"],
parseNumber_or_fraction(studentAnswer,settings["notationStyles"])
,
parseNumber(studentAnswer,settings["notationStyles"])
)
isFraction (Is the student's answer a fraction?):
"/" in studentAnswer
numerator (The numerator of the student's answer, or 0 if not a fraction):
if(isFraction,
parseNumber(split(studentAnswer,"/")[0],settings["notationStyles"])
,
0
)
isInteger (Is the student's answer an integer?):
countDP(studentAnswer)=0
denominator (The numerator of the student's answer, or 0 if not a fraction):
if(isFraction,
parseNumber(split(studentAnswer,"/")[1],settings["notationStyles"])
,
0
)
cancelled (Is the student's answer a cancelled fraction?):
gcd(numerator,denominator)=1
validNumber (Is the student's answer a valid number?):
if(isNaN(studentNumber),
warn(translate("part.numberentry.answer invalid"));
fail(translate("part.numberentry.answer invalid"))
,
true
)
numberInRange (Is the student's number in the allowed range?):
if(studentNumber>=settings["minvalue"] and studentNumber<=settings["maxvalue"],
correct()
,
incorrect();
end()
)
correctPrecision (Has the student's answer been given to the desired precision?):
if(togivenprecision(studentanswer,settings['precisionType'],settings['precision'],settings["strictPrecision"]),
true
,
multiply_credit(settings["precisionPC"],settings["precisionMessage"]);
false
)
mark (Mark the student's answer):
apply(validNumber);
apply(numberInRange);
assert(numberInRange,end());
if(isFraction,
apply(cancelled)
,
apply(correctPrecision)
)
interpreted_answer (The student's answer, to be reused by other parts):
studentNumber
You can write your own marking algorithm for any part. If you use the built-in part types, this a great way of quickly changing the way the part is marked: for example, you could make the number entry part accept any number equivalent to the expected answer modulo a given base by changing the studentNumber note.
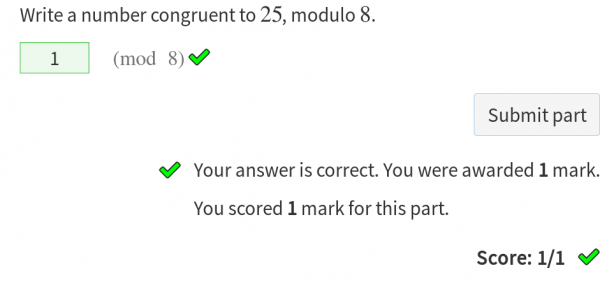
This part uses a marking algorithm which compares the student’s answer and the expected answer modulo a given base.
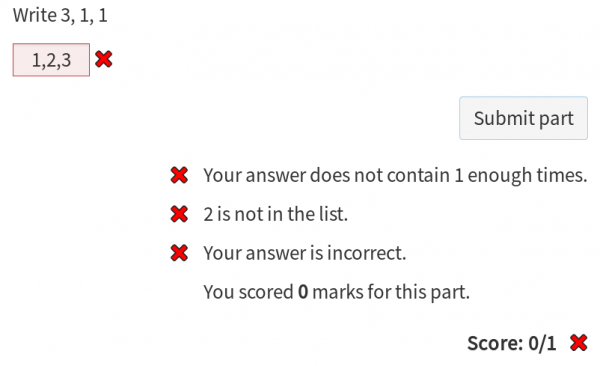
This part uses a marking algorithm which interprets the student’s answer as a list of numbers.
This new system opens up a world of possibilities for inventive questions. I’ve lately found myself repeatedly saying to colleagues asking for questions on new subjects, “Numbas doesn’t really do that at the moment, but it’ll be easy with the new marking algorithms”. So, now that they’re here, I have to follow up on that and write a bunch of interesting questions!
Read the Numbas documentation for more about how marking algorithms work.
Custom part types
It very quickly became clear that a good marking algorithm will be reused a lot, so we need to make that as easy as possible. Copying-and-pasting scripts between parts could end up in having a myriad slightly-different versions of the same thing lying around, and fixing bugs would mean changing each one individually.
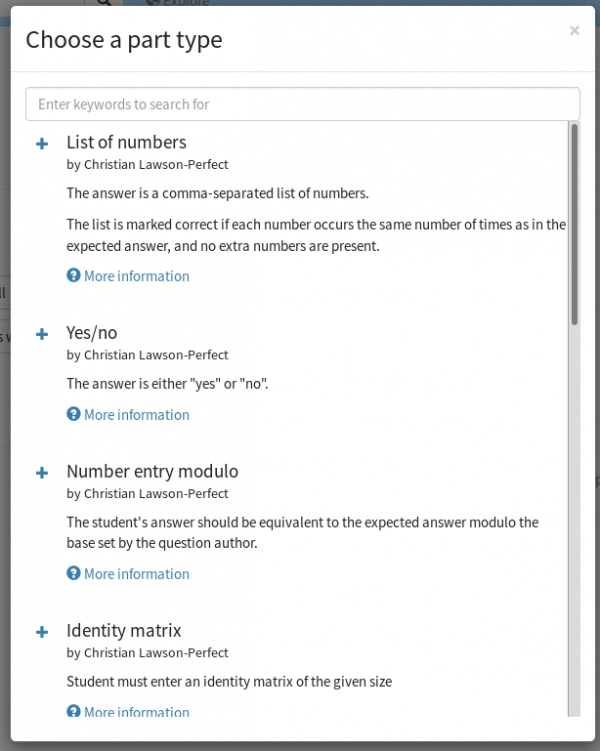
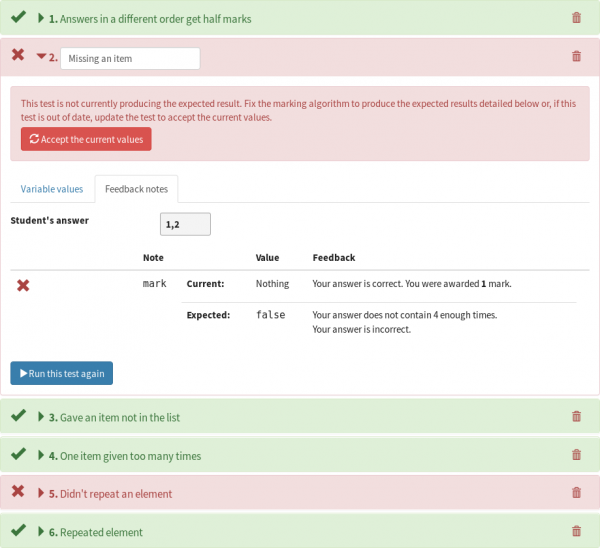
A new pop-up in the question editor shows available custom part types.
So, I’ve introduced custom part types to the editor. To make a custom part type, you need to pick a method for the student to enter their answer, give a list of settings to allow question authors to configure the part’s behaviour, and finally write a marking algorithm.
This is all achieved through a new editor interface, similar to the question and exam editors.
The custom part type editor.
Inside the question editor, custom part types work just like the built-ins: when creating a part, you select its type, and then write a prompt and fill in the settings. Less proficient question authors can use custom part types without any knowledge of the underlying mechanisms.
Numbas is all about sharing, so it’s possible to publish your custom part type to the public database and allow anyone to find and use it. By publishing more custom part types, Numbas will become more versatile than ever!
Read the Numbas documentation for more about how custom part types work, or check out this demo question featuring a few simple custom part types.
Testing the marking algorithms
With great power comes great responsibility. It’s important to know that a custom marking algorithm works properly on whatever answer the student gives, both correct and incorrect.
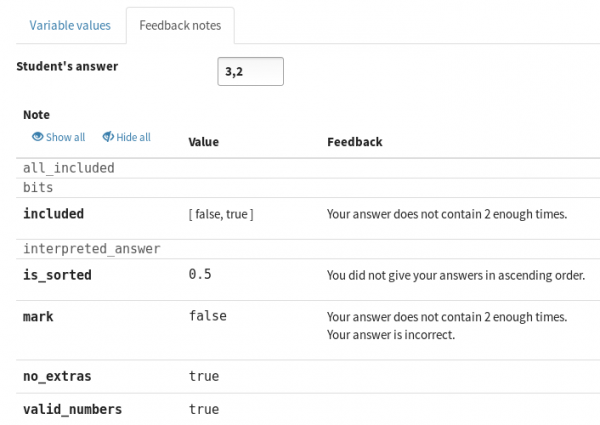
Each question part now has an interface to test its marking algorithm against different answers. After entering an answer, you can see the feedback produced for each note in the algorithm, and save the results as a unit test. If you make changes to the part, you can re-run the unit tests to confirm that you get the expected results.
Other changes
The editor documentation has moved to docs.numbas.org.uk. The old readthedocs address still works, but we thought it would be better to have the documentation under a Numbas-specific domain.
I’ve taken the opportunity to do some spring-cleaning and take a fresh look at parts of the editor and runtime interfaces.
Changes in the runtime
The box containing the “submit part” button and feedback messages is no longer a box, and all feedback elements are always visible. This allows students to submit empty answers (sometimes that might be the right thing to do!), and makes the written feedback much more prominent – we’ve got the impression that students haven’t been clicking on the “Show feedback” button very often. Feedback items which add or subtract marks show a tick or a cross, giving an easily-read summary of how the part was marked.
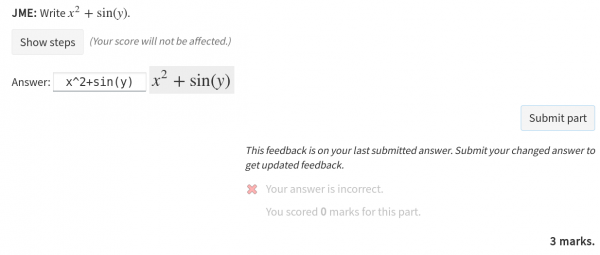
Part feedback is always visible, but if you change your answer it gets greyed out until you re-submit.
New simplification rules cancelTerms, cancelFactors, canonicalOrder and expandBrackets are the first step in allowing more of the functionality that a computer algebra system should offer. These rules concentrate on improving the handling of polynomials, so terms are displayed in decreasing order of degree, and common terms can be collected together.
When a Numbas exam is running completely stand-alone, the student is warned that their answers won’t be saved anywhere. (issue)
There have been plenty more internal changes, detailed below:
- Ranges are only enumerated when necessary (code) – this vastly speeds up questions which pick from very wide ranges of numbers. We had a question which picked a number between 1 and 1,000,000 which was embarrassingly slow. Now it’s lightning fast!
- There are some new strings to translate (sorry, translators!)
- Questions and parts can run standalone, without the rest of the Numbas runtime. This means we can now automatically test more of the code, and could open up new opprtunities for embedding Numbas questions outside of the normal SCORM package context.
NaNis a number in JME (code)Part.answerListis no more (code)- Removed the dependency on jQuery in non-display runtime code.
- The JME parser is now an object, which can be given options, such as silently inserting missing function arguments or closing unmatched brackets (code)
- When you change your answer to a step, the parent part is not marked as changed. (code)
- Catch errors caused by Knockout.js bindings in the default theme. (code)
- There is a JME ‘nothing’ value, introduced for marking notes which don’t need to produce a usable value.
New JME functions
While converting the old marking algorithms to JME, I found I needed a lot of things that just weren’t available. So, this update comes with quite a few new JME functions. Click on any of the function names below to go to its documentation.
all, args, assert, canonical_compare, cleannumber, countdp, countsigfigs, definedvariables, exec, findvars, formatstring, isbool, isnan, letterordinal, match, match_regex, matches, name, nonemptyhtml, numcolumns, numrows, op, parse, parsenumber_or_fraction, replace, resultsequal, simplify, some, togivenprecision, translate, trim, try, type, unpercent, withintolerance.
Changes in the editor
For those installing their own instance of the editor, there’s now a script which automatically configures the editor on installation, based on your answers to a few questions. That should mean a lot less stuff to read
The “Parts” tab in the question editor is now laid out more like the “Variables” tab – there’s a list of parts on the right, and the editing interface on the left only shows the currently-selected part. This vastly reduces the amount of scrolling around, and should also make the editor much faster. Reordering parts is a bit easier now – rather than repeatedly pressing the “move up/down” arrows, you can drag and drop in the parts list.
With a view to GDPR compliance, it’s now possible to deactivate your account on the editor, and each page now has a footer containing links to a terms of use/privacy policy page, which site admins must write. When a user deactivates their account, all personal information is wiped but any content they have created and not reasssigned to another user remains on the database, attributed to “Deactivated user”. Site admins can reassign this content to other users if required.
Here are the other changes since the last development log:
- When you reload the question editor, each part is open at the tab you were (code)
- In the question variables preview, show lists in their entirety if short enough. (code)
- Instance admins can now specify the location of the editor documentation with the HELP_URL setting.
- Dictionary values are now shown as “Dictionary with N entries” in the variable preview, instead of an unreadable long string. (code)
- When you change the name on your account, your personal workspace’s name is automatically updated. (code)
- You can’t change the type of an existing part any more. Instead, you should delete the unwanted part and create a new one of the right type.
- The rich text editor doesn’t add
<p>tags to content that’s going to end up inline (code)
If you run your own instance of the editor, run the following commands:
> pip install --upgrade -r requirements.txt > python first_setup.py
Changes in the Numbas LTI provider
It’s been a while since I last discussed development on the LTI provider, so I’ll do that here.
I think we’re finally on top of the various out-of-sync errors that can occur when a student’s connection to the server is slow or interrupted. All attempt data is timestamped and counted, so the server can always work out the latest version of a particular item. If there’s a problem saving data, a red warning box is shown to the student, which becomes a very big red warning box when the exam ends. They’re told to wait and see if the connection is re-established, to try completing the exam on another machine, or to email a support contact.
I’ve begun writing some detailed documentation for the LTI provider, currently available at numbas-lti-provider.readthedocs.io. It’s a work in progress, but contains quite detailed installation instructions. I’ve also streamlined the installation process, following the same pattern as the editor: you install all the dependencies, and a script finishes the rest of the configuration based on your answers to some questions.
The provider’s admin interface lists all the courses for each consumer, and then all the resources belonging to each course. You can click on a resource to open the instructor dashboard, where you can change the exam’s settings and manage student attempts.
The attempts dashboard for instructors now shows a ‘heatmap’ next to each attempt describing the student’s scores at each question in the exam.
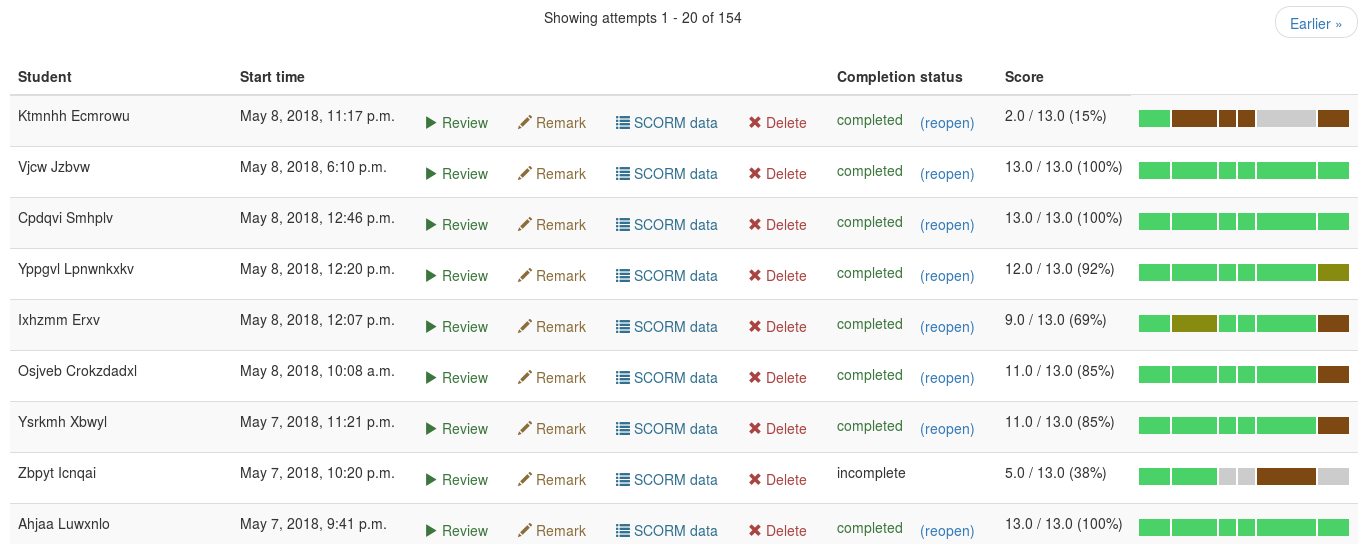
Heatmaps for each student attempt at an exam.
It used to be possible for a student to open the same attempt in two browser windows, end the attempt in one, and copy the expected answers into the other. The server now refuses to save any data created after the attempt has been completed. If the same attempt is opened in two windows at the same time, the older session is automatically terminated.
Here are some other recent changes:
- Instructors can reopen attempts that were ended by accident.
- There’s an option to never show scores to students, even for completed attempts.
- Lots of information about attempts is cached in the database, to make the reporting and instructor interfaces faster.
- Errors saving to the database are handled silently.
- You can define a URL for each consumer to open its homepage from the admin interface.
- When selecting projects to use from a linked editor, the name of the project’s owner and numbers of published questions and exams are shown next to each project.
That’s a lot of changes!
We’ve spent a long time on this update, honing the design and testing it with our internal material. Please give it a go now, and let us know how you get on. You can contact us through the Numbas users group, or email us directly at numbas@ncl.ac.uk.
Thanks to those who have contributed code or translations – you made Numbas better!