We’re releasing another major version of Numbas. This release incorporates a couple of exciting new developments, which greatly expand Numbas’ capabilities.
If you want to dive right in, have a go at the demo exam we’ve made to show off the new features.
Pattern-matching
In Numbas, we have two related tasks: give feedback based on the form of a student’s answer, and “simplify” expressions according to a configurable set of rules.
Both of these tasks involve pattern-matching in some form: to give feedback, different forms of algebraically equivalent expressions must be described in some general way; to simplify an expression, a rewriting rule must recognise expressions in a certain form and identify particular sub-expressions to produce a new form.
Numbas has always had a pattern-matching system which powers the simplification rules. I’ve spent the majority of the last year working on an entirely new pattern-matching system. It’s much more powerful, allowing us to express quite sophisticated patterns using a concise and fairly readable syntax.
I hope to write in more detail about the design of the pattern-matching system and its implementation, but here I’ll just show how you can use it in Numbas.
First of all, the syntax has changed from previous versions of Numbas. Very few people actually used the pattern-matcher directly, so this is more of a new feature than a change. There is documentation on the syntax and how it works, which I intend to add to and improve.
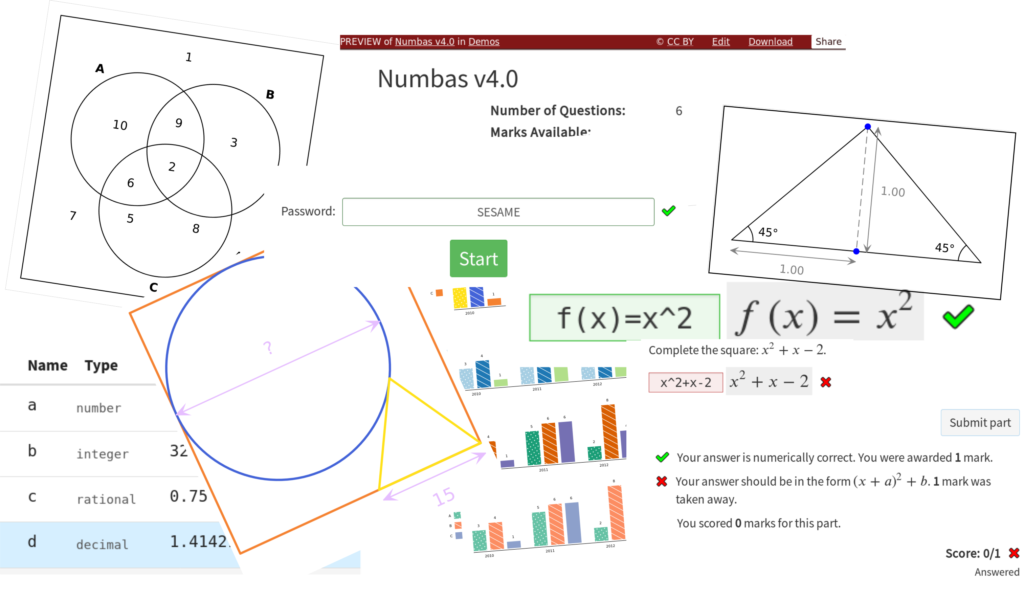
The most important new feature that the new pattern-matching syntax enables is the pattern restriction option for mathematical expression parts. You can specify a pattern that the student’s expression must match in order to be marked correct. If it doesn’t, they either get a penalty or their answer is marked incorrect. This means you can now set questions that look at the form of the student’s answer.
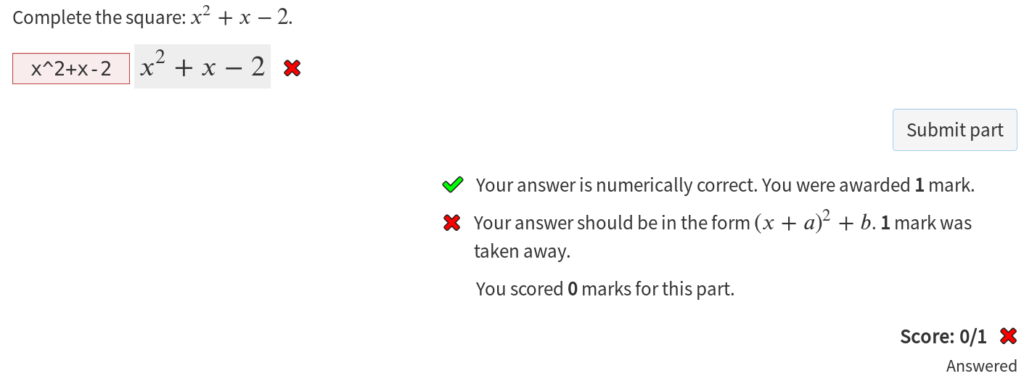
There’s also the option to only compare a certain part of the student’s expression against the corresponding part of the expected answer. This allows you to mark formulas of the form \(f(x) = \ldots\), by only comparing the part of the expression to the right of the equals symbol, avoiding the \(f(x)\), which can’t be evaluated to a number.
Stuff to do with parsing JME syntax has been consolidated. This doesn’t have any obvious effects for users, but opens up some possibilities for new features in the future. You can now create customised parsers, which is how the pattern-matching syntax was implemented. I hope to use this in the future to allow the student to use context-specific notation, such as interval notation or group presentations.
Because a few aspects of the internals of the Numbas runtime have changed, questions which use the pattern-matching system through custom JavaScript might need to be changed. We’ve looked at the public Numbas editor’s database and didn’t find anyone outside Newcastle who did this. Anyone using a local instance of the Numbas editor should check their questions carefully for breaking changes when upgrading to Numbas v4.
Have a look at the documentation for the new pattern-matching syntax, and for the pattern restriction on mathematical expression parts.
More number types, and automatic conversion
Arithmetic in Numbas has always used JavaScript’s built-in number representation. The vast majority of the time, this works well, because a lot of thought has gone into JS’s number representation. However, it’s a compromise, and errors start to accumulate when working with very large or small numbers, or even after quite innocuous-seeming operations like division by odd integers. The built-in numbers can only be relied on to be accurate to about 14 decimal places, and even that precision is lost at very high and very low orders of magnitude.
Numbas does a lot of work to smooth out these problems, but for a long time I’ve wanted Numbas to have a more robust means of working with high-precision numbers.
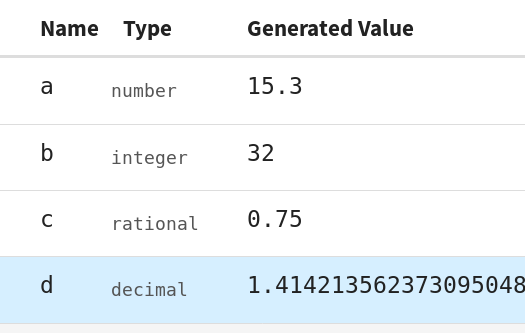
So, I’ve rewritten the JME data type system to allow a selection of “number-like” data types, with automatic conversion between them. There’s now a decimal type, powered by the excellent Decimal.js library, as well as integer and fraction types for working with rational numbers without losing precision. These types all get converted to the standard number when necessary, so you can use them seamlessly with
Additionally, many of the “collection-like” types such as range, set, matrix and vector can automatically be converted to list data, so you can pass them straight into any function that takes a list.
The “number entry” part type uses the decimal data type in its marking algorithm, so you can mark high-precision numbers easily.
There’s a new number notation style, scientific, which renders and parses numbers in the form MeP, where M is a decimal in the interval \([1,10)\) and P is an integer, e.g. 6.022e23.
example number entry question with big decimal
Finally, I’ve updated the quantities extension to store the scalar part as decimal data, so you can work with very large or very small physical quantities without losing precision.

Automatic testing of questions

The changes in this version of Numbas affect many of the core features of the system, so we wanted to take extra care making sure that nothing had broken.
I’ve written an automatic testing framework which runs through all of the questions in the Numbas editor database, verifying that they run as expected. It does a test run of each question, and tries submitting the expected answer for each part. If something has broken, then either the test run will fail to start, or the marking won’t produce the expected result.
By running this tool against all the questions on our internal database, we found a few edge cases and bugs in the new code, but we were glad to see that pretty much everything worked as before. Right now, all of our questions work in Numbas v4 as they did before. The only thing I needed to change was to replace custom JavaScript in a handful of old questions with the new pattern-matching syntax.
There are a few aspects of the system that the automatic testing can’t look at, particularly the interface as it appears to the student. We’ve spent a lot of time manually running tests in a variety of browsers to check that nothing has broken.
Embeddable questions and exams
The “Test Run” view has been improved: there’s now a banner at the top of the page giving links back to the editor, and there’s a “share” link to show the item without this banner.
Previously, previews were periodically deleted to make space. This link is now permanent, so can be safely shared – the preview is recompiled on access if it’s been cleaned up previously.
You can embed a Numbas question or exam into a blog post just by pasting its address into WordPress. This is made possible by the fact that published questions and exams can now be discovered by oEmbed providers.
I think teachers in particular will find this useful: you can write a question on the Numbas editor, and include it in a blog post in a matter of seconds!
Here’s a question from our “transition to university” project. The question is being served from the Numbas editor, and running entirely in your browser.
Note that Numbas resources embedded this way aren’t linked up to a learning environment of any sort, so student attempt data isn’t recorded. They’re perfect for students who want to practise on their own, though!
Eukleides extension
The JSXGraph extension has been part of Numbas for years, and we’ve used it quite successfully. However, it’s not simple to use: you have to write a lot of JavaScript code to create a JSXGraph diagram, which limits its use to a technically-minded subset of question authors.
At the other end of the spectrum, we can use GeoGebra‘s graphical editor to create interactive diagrams very easily, but it’s quite a convoluted process: you have to create a worksheet at geogebra.org, copy its address, and then work out how question variables correspond to GeoGebra variables. The applet is very heavy, and can’t be included with the downloaded exam package, so if geogebra.org ever changes how it works (something that I don’t think is likely, I should say), Numbas packages using it would need to be updated.
Eukleides is a geometrical drawing language which I have admired for a very long time. It provides a few simple tools for creating diagrams, prioritising readability over sophistication. However, it was written in C in order to produce PostScript files, and hasn’t seen any development work in almost a decade.
I’ve rewritten Eukleides from scratch in JavaScript, and created a Numbas extension which integrates the Eukleides routines with JME syntax.
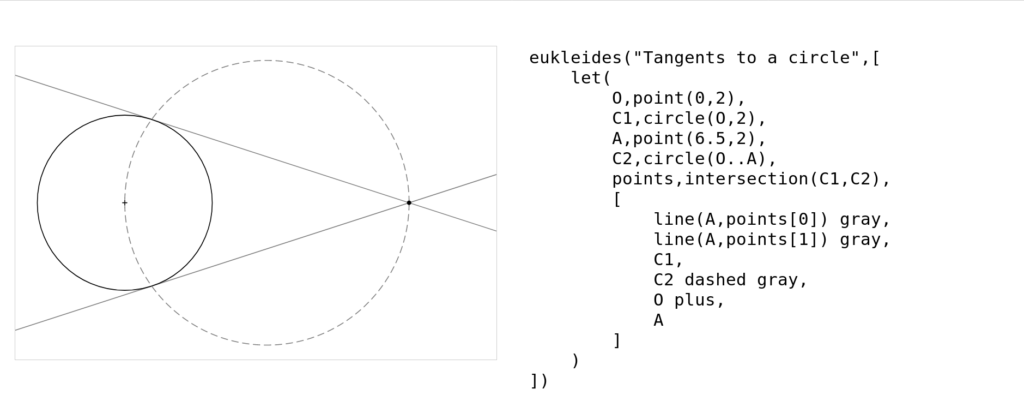
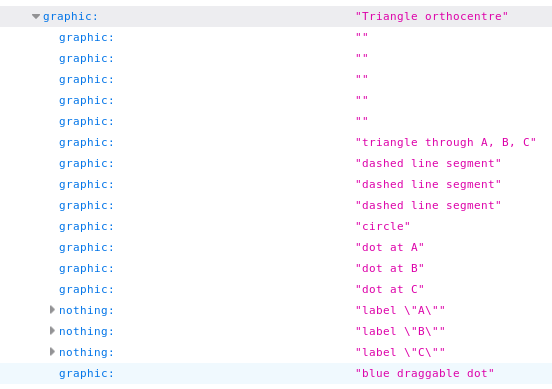
I’ve put a lot of thought into accessibility for Eukleides diagrams. The extension automatically provides descriptions of objects to the browser’s accessibility tree, which is used by assistive technology such as screen readers. For example, a triangle through points A, B and C will be described as “triangle through A, B, C”. Authors can add custom descriptions to provide further semantic information, such as “circle circumscribed in square ABCD”.
A common accessibility problem with diagrams is poor choice of colours, which can be hard to distinguish for people with poor eyesight or colour vision deficiency. I’ve drawn on the excellent ColorBrewer project to provide a selection of accessible colour schemes. To specify colours, you don’t use names like red and green: instead there are a set of built-in colours named color1 to color6 which have been chosen to be easy to distinguish for 99.99% of people. Finally, you can add a pattern of dots or dashes to further distinguish elements.
Finally, it’s really easy to make Eukleides diagrams interactive. Borrowing an idea (and a little bit of code) from the library g9.js, making a diagram interactive is as simple as marking a point as “draggable”. When the user tries to drag a draggable point, it uses a numerical solver to find a set of values for the free variables in the diagram’s definition which draws the point where the user has moved it.
This is a really neat way of providing interactivity, without forcing the author to explicitly account for it in the diagram’s definition script.
For example, in a diagram showing a triangle defined by the length of one of its sides and an internal angle, you can make the orthocentre of the triangle draggable, and it’ll automatically change the two parameters to move the dragged point where it’s needed.
You can also create animations very easily – the variable time is set to the number of seconds since the diagram was created. The diagram is continually redrawn with the latest value of time.
Because diagrams are defined using JME code, you can easily include question variables, so the diagram shown to the student reflects the values shown elsewhere in the text.
There’s full documentation, as well as a page of example diagrams and a playground where you can create your own, outside the Numbas editor. I’ve prepared a small demo exam from a couple of questions containing Eukleides diagrams.
Other changes
Numbas runtime
- Student can press the enter key to submit a custom part type answer (issue)
- Catch when a setting for a custom part type is incorrectly empty (issue)
- The printed worksheet theme shows the number of marks available for parts and questions (issue)
- The score display and the ‘answered’/’unanswered’ states are now displayed separately. There’s a ‘partially answered’ state for questions where only some parts have been answered. (code)

- Number entry parts round the minimum and maximum expected value to the same precision the student used, before comparing. (issue, documentation)
- You can now specify a step size when slicing lists:
list[a..b#c]picks everycelements between indexaandb. (code) - The JME function
parsenumbernow returnsNaNif the string doesn’t match any of the allowed styles, instead of attempting to parse it as a JavaScript number. (code) - The
mixedFractionsdisplay flag causes numbers to be displayed as mixed fractions. (code, documentation) Numbas.jme.tokenComparisonsis a dictionary of functions for comparing JME values, so extensions which add new data types can easily make them comparable. (code)- Non-marked parts aren’t counted when determining if a question has been answered. (code)
- When a gap-fill part is worth 0 marks, the feedback messages still show positive/negative icons based on the proportion of credit awarded. (code)
- The student’s answer to a “mathematical expression” part is simplified with the “basic” rules before being compared to the correct answer or applying any pattern restrictions. (code)
- The “submit part” button isn’t shown when there’s only one part in a question. Instead, there’s just the “submit answer” button at the bottom. (issue)
- The simplification rule
noDivisionreplaces all division with multiplication by a power of-1. (code) - If an error occurs while performing adaptive marking, the answer is marked as incorrect and the student is told that the answer could not be marked using their answers to previous parts. (code)
- There’s a “show choice feedback state” option for the multiple choice part types. If enabled, selected options are highlighted based on whether they add or subtract from the score. (code, documentation)
- Any strings in the student’s answer to a part are marked as “safe”, so question variables aren’t substituted into them if they include curly braces. (code)
- Parts with one step show a submit button for the step. (issue)
- If a marking algorithm ends up awarding more than 100% credit for a part, it’s limited to 100% and the student is shown a message. (code)
- “Mathematical expression” parts can now infer the types of variables used in the answer, and generated random values accordingly. The question author can optionally write their own expressions to generate values for particular variables. (issue, code)
- In the default theme, the question statement now has the same background colour as the part prompts. (code)
- The “expected variable names” setting for mathematical expression parts has been removed. Now, the warning is shown if the student uses any variable names not present in the expected answer. (code)
- When revealing answers for a part with “always replace answers” adaptive marking, the “expected answer” displays the answer calculated using the adaptive marking replacements. (issue)
- When “show feedback icon” is turned off, feedback messages which affect the part credit are not shown. (code)
- The exam author can specify a password which the student must enter before they can begin the exam. (issue)

- The
letfunction can assign a different name to each of the elements of a list. (code) - Parts can be given custom names, or no name at all, overriding the default alphabetic sequence. (issue)
- “Information only” parts have no name and aren’t counted when working out the names for other parts. (issue)
- To make it more obvious that students can review their feedback after completing an exam, each row in the question results table now has a link labelled “Review” to view that question. (issue)
- “Number entry” parts automatically sort the minimum and maximum expected value, so the right interval is marked even if the question author gets them the wrong way round. (issue)
- Part warnings have been made more accessible, and more prominent – the warning box is visible whenever the input box has focus (always, for multiple response parts). (issue)
- There’s a “show fraction input hint” option for “number entry” parts – the student is told “give your answer as a reduced fraction” when appropriate. (issue)
- Part feedback messages have a brief ‘pulse’ animation after submitting a part, to signify that they’ve been updated. (code)
- Submitting a part with no answer no longer results in an error message. Instead, a warning is shown. (issue)
- When regenerating a question with no marks available, marks are not mentioned in the warning message. (issue)
- Clicking an image in a content area expands it to fill the screen, so you can see more detail. (issue)
- Part credit is stored as a fraction, not a float, so no accuracy is lost when adding up credit for gap-fills. (issue)
- If marking fails because a “must be answered” part used in adaptive marking hasn’t been answered, the student is told so. (issue)
Editor
- The system keeps track of who has contributed to a question or exam by editing it. The list of contributors is shown on the “Settings” tab, and a count is shown in search results. The contributor information is retained in downloaded source files, and when re-uploaded to any instance of the Numbas editor. (issue)
- When writing a custom marking algorithm for a part, the built-in marking algorithm is shown above, for reference. (code)
- When changing a search query, any filters set in the sidebar are preserved. (issue)
- Custom part types can require that certain extensions are enabled – these are automatically enabled when you add a part of that type to a question. (code, documentation)
- There’s a global stats page showing things like numbers of questions and exams, user sign ups, and projects. The one for the mathcentre editor is at numbas.mathcentre.ac.uk/stats. (code)
- A variable whose value is a large set is displayed as “Set of N items” in the preview table. (issue)
- When setting a variable replacement for adaptive marking, you select the name of the variable to replace from a list instead of typing it. (issue)
- String variables can be marked as templates, so variables are not substituted into them. The
renderfunction can be used to substitute variables into strings subsequently. (issue) - The Numbas editor documentation is now part of the editor repository, instead of in its own repository.
- Text about the terms of use and privacy policy are shown on the signup form. (code)
- In the question variable preview table, there’s now a column showing the data type of each variable. (issue)
- You can reassign all of your content to someone else. There’s a prompt to do this while deactivating your account. (issue)
- Your five most recently-viewed items are shown on the homepage. (issue)
- Gaps and steps can be reordered by dragging and dropping. (issue)
- While editing a gap or step, there’s an “add another gap/step” button, so you don’t have to go back up to the parent part first. (issue)
- There are some prompts under the “Description” field in the question editor about what you should include. (issue)
LTI provider
- There’s a “statistics” tab in the management view for each resource. At the moment it shows a breakdown of attempts by completion status, and the distribution of scores as a graph. (issue)
- The admin interface has a “stress test” facility. This opens up a large number of connections to a fake Numbas exam, to test how the LTI provider copes under high usage. (issue)
- You can delete a context (normally corresponding to a course in a VLE) and all resources and attempts belonging to it. (issue)
- For each consumer, you can specify time periods to group contexts under. We use this to group courses by semester. (issue)
Localisation
There are new pieces of text in the Numbas interface that need to be localised. If you speak a language in addition to English, please go to our localisation page and write some translations.
We now have eleven languages with at least half of the text translated, and six full translations. Thanks again to everyone who has helped to translate Numbas so far!
Contributors
Thanks to the following people for contributing code to Numbas in the last year:
- Christian Lawson-Perfect
- Chris Graham
- Mohit Jayanti Gurumukhani
- RingoKid
- Johan Forslund
- Joshua Capel
- Adarsh Shetty
There are always plenty of opportunities for you to start contributing to Numbas. See our page on contributing to Numbas for more information. Our GitHub issues labelled “good first issue” are a good place to start.
Give it a go!
You can use all these new features right now on numbas.mathcentre.ac.uk. If you run your own instance of the Numbas editor, follow the upgrade instructions in the documentation.
If you have any questions about the new features, or spot a bug, you can post on the Numbas user group, file an issue on GitHub, or email us.